코드스테이츠 2주차 - 객체지향 프로그래밍 기초(필드와 매서드)
필드(Field)
필드는 ‘클래스에 포함된 변수'를 의미하는 것으로 객체의 속성을 정의할 때 사용됩니다.
자바에서 변수는 크게 클래스 변수(cv, class variable), 인스턴스 변수(iv, instance variable), 그리고 지역 변수(lv, local variable)라는 세 가지로 구분될 수 있습니다.
이 중 우리가 필드라 부른 것은 클래스 변수와 인스턴스 변수이며, 이 둘은 다시 static 키워드의 유무로 구분할 수 있습니다.
좀 더 구체적으로, static 키워드가 함께 선언된 것은 클래스 변수, 그렇지 않은 것은 인스턴스 변수입니다. 그리고 이 두 가지 변수 유형에 포함되지 않고 메서드 내에 포함된 모든 변수를 지역변수라 부릅니다.
이 세 가지 유형의 변수들은 주로 선언된 위치에 따라 그 종류가 결정되며 각각 다른 유효 범위(scope)를 가지게 됩니다. 아래 예시를 통해 한번 살펴보겠습니다.
이 세 가지 유형의 변수들은 주로 선언된 위치에 따라 그 종류가 결정되며 각각 다른 유효 범위(scope)를 가지게 됩니다. 아래 예시를 통해 한번 살펴보겠습니다.
class Example { // => 클래스 영역
int instanceVariable; // 인스턴스 변수
static int classVariable; // 클래스 변수(static 변수, 공유변수)
void method() { // => 메서드 영역
int localVariable = 0; // 지역 변수. {}블록 안에서만 유효
}
}
위의 코드 예제에서 Example 클래스 안에 앞서 언급한 세 가지 유형의 변수가 선언되어져 있습니다. 이 중에 instanceVariable 과 classVariable 은 클래스 영역에 선언되었기 때문에 멤버 변수입니다.
다시 static 키워드(이어지는 챕터에서 학습 예정)의 유무에 따라 classVariable 변수가 클래스 변수, 그리고 키워드가 있지 않은 instanceVariable 변수가 인스턴스 변수가 됩니다.
마지막으로 메서드 내부의 블럭에 선언되어있는 지역변수 localVariable 이 있습니다.
이처럼 변수는 주로 그 선언 위치와 static 키워드의 유무에 따라 구분할 수 있습니다. 이제 각각에 대해서 좀 더 자세히 살펴보겠습니다.
먼저 인스턴스 변수(iv)는 인스턴스가 가지는 각각의 고유한 속성을 저장하기 위한 변수로 new 생성자() 를 통해 인스턴스가 생성될 때 만들어집니다.
클래스를 통해 만들어진 인스턴스는 힙 메모리의 독립적인 공간에 저장되고, 동일한 클래스로부터 생성되었지만 객체의 고유한 개별성을 가집니다.
마치 사람마다 성별, 이름, 나이, MBTI가 다 다르듯 인스턴스 변수는 그 고유한 특성을 정의하기 위한 용도로 사용됩니다.
다음으로, static 키워드를 통해 선언하는 클래스 변수(cv)가 있습니다. 클래스 변수는 독립적인 저장 공간을 가지는 인스턴스 변수와 다르게 공통된 저장공간을 공유합니다.
따라서 한 클래스로부터 생성되는 모든 인스턴스 들이 특정한 값을 공유해야하는 경우에 주로 static 키워드를 사용하여 클래스 변수를 선언하게 됩니다. 사람을 예로 들면 손가락과 발가락 개수와 같이 모든 사람이 공유하는 특성을 저장하는 데에 사용됩니다.
또한, 클래스 변수는 인스턴스 변수와 달리 인스턴스를 따로 생성하지 않고도 언제라도 클래스명.클래스변수명 을 통해 사용이 가능합니다. 위의 코드 예제로 예를 들면, Example.classVariable 로 클래스 변수를 사용할 수 있습니다.
참고로, 이것은 앞서 봤었던 메모리 구조에서 메서드처럼, 클래스 변수 또한 클래스 영역에 저장되어 그 값을 공유하기 때문에 가능합니다.
마지막으로 앞서 설명한 두 가지의 멤버 변수와 구분되는 지역변수(lv)가 있습니다. 지역변수는 메서드 내에 선언되며 메서드 내({} 블록)에서만 사용가능한 변수입니다.
멤버 변수와는 다르게 지역변수는 스택 메모리에 저장되어 메서드가 종료되는 것과 동시에 함께 소멸되어 더이상 사용할 수 없게 됩니다.
또한 힙 메모리에 저장되는 필드 변수는 객체가 없어지지 않는 한 절대로 삭제되는 않는 반면, 스택 메모리에 저장되는 지역변수는 한동안 사용되지 않는 경우 가상 머신에 의해 자동으로 삭제됩니다.
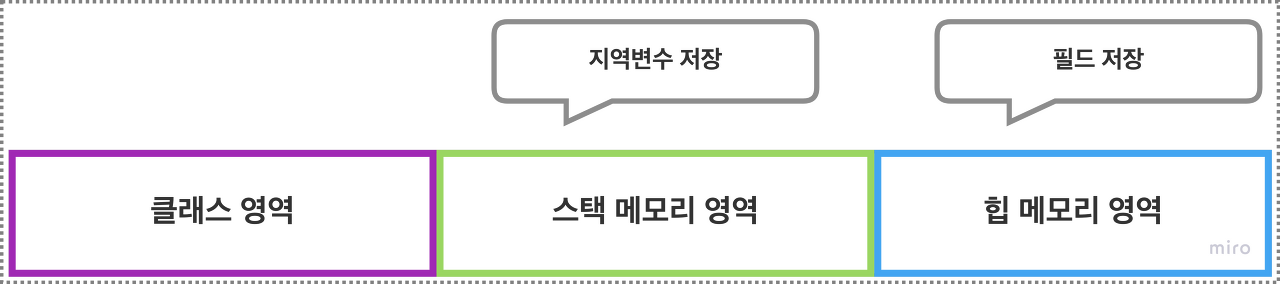
마지막으로 필드 변수와 지역 변수의 주요한 한 가지 차이점은 초기값에 있습니다.
직접 초기화하지 않으면 값을 출력할 때에 오류가 발생하는 지역변수와는 다르게 필드 변수는 직접적으로 초기화를 실행하지 않더라도 강제로 초기화가 이뤄집니다.
이것 또한 메모리의 저장 위치와 긴밀한 연관성을 가집니다. 힙 메모리에는 빈 공간이 저장될 수 없기 때문에 이곳에 저장되는 필드는 강제로 초기화되지만, 스택 메모리는 강제로 초기화되지 않으므로 지역 변수는 선언시 반드시 초기화를 실행해주어야 합니다.
static 키워드
앞선 챕터에서 우리는 클래스 변수와 인스턴스 변수를 구분하기 위한 방법으로 static 키워드의 유무를 확인한다고 배웠습니다. 이번 챕터에서는 static 키워드에 대해서 좀 더 알아보겠습니다.
static은 클래스의 멤버(필드, 메서드, 이너 클래스)에 사용하는 키워드입니다.
static 키워드가 붙어있는 멤버를 우리는 ‘정적 멤버(static member)’라고 부르고 static이 붙어있지 않은 인스턴스 변수와 구분합니다.
이 둘을 구분하는 가장 큰 차이는 인스턴스 멤버는 기존에 우리가 배웠던 내용처럼 반드시 객체를 생성한 이후에 변수와 메서드에 접근하여 해당 멤버를 사용가능한 반면, static 키워드로 정의되어 있는 클래스 멤버들은 인스턴스의 생성 없이도 클래스명.멤버명 만으로도 사용이 가능하다는 점입니다.
물론 정적 멤버도 객체를 생성한 이후 참조변수를 통해 사용이 가능하지만, 애초에 정적 멤버임을 표시하기 위해서 클래스명.멤버명 의 형태로 사용할 것을 권장하고 있습니다.
static 키워드를 사용하는 정적 멤버를 클래스명.멤버명 으로 사용할 수 있는 것 또한 앞에서 봤었던 메모리의 저장 위치와 관련이 있습니다. 앞서 확인했듯이 new 키워드를 통해 생성된 인스턴스는 힙 메모리에 생성되고 독립적인 저장공간을 가지게 됩니다.
반면 static 키워드로 선언된 정적 멤버는 클래스 내부에 저장 공간을 가지고 있기 때문에 객체 생성 없이 곧바로 사용할 수 있습니다.
정말 그런지 코드를 통해 직접 확인해보겠습니다.
public class StaticTest {
public static void main(String[] args) {
StaticExample staticExample = new StaticExample();
System.out.println("인스턴스 변수: " + staticExample.num1); // static 키워드가 없는 인스턴스 변수
System.out.println("클래스 변수: " + StaticExample.num2); //static 키워드가 있는 클래스 변수
}
}
class StaticExample {
int num1 = 10;
static int num2 = -10;
}
//출력값
인스턴스 변수: 10
클래스 변수: -10
위의 예시를 보면 static 키워드의 유무에 따라 달라지는 차이를 명확하게 확인해볼 수 있습니다.
실험을 위해, 먼저 StaticExample 클래스에 static 키워드가 있는 변수 num2 와 static 키워드가 없는 변수 num1 에 각각 -10과 10을 할당했습니다. 그리고 StaticTest 클래스에서 각각의 필드 값을 호출했습니다.
다만 인스턴스 변수는 우리가 아는 일반적인 방법으로 객체 생성 후에 포인트 연산자를 사용하여 값을 불러왔고, 클래스 변수는 객체 생성 없이 클래스명을 사용하여 값을 불러왔습니다. 직접 인텔리제이를 사용하여 값이 정상적으로 호출되는 지 확인해봅시다.
여기서 우리가 기억해야 할 것이 두 가지가 있습니다.
먼저, 정적 필드는 객체 간 공유 변수의 성질이 있다는 점입니다. 이것은 메서드에도 동일하게 적용됩니다. 일반적인 메서드 앞에 static 키워드를 사용하면 해당 메서드는 정적 메서드가 됩니다. 정적 메서드도 정적 필드와 마찬가지로 클래스명만으로 바로 접근이 가능합니다.
둘째, 정적 메서드의 경우 인스턴스 변수 또는 인스턴스 메서드를 사용할 수 없다는 것입니다. 이 점은 잘 생각해보면, 사실 너무 당연한 이야기입니다. 정적 메서드는 인스턴스 생성 없이 호출이 가능하기 때문에 정적 메서드가 호출되었을 때 인스턴스가 존재하지 않을 수 있기 때문입니다.
이제 정적 필드 간에 값 공유가 일어나는 것을 코드로 한번 살펴보겠습니다.
public class StaticFieldTest {
public static void main(String[] args) {
StaticField staticField1 = new StaticField(); // 객체 생성
StaticField staticField2 = new StaticField();
staticField1.num1 = 100;
staticField2.num1 = 1000;
System.out.println(staticField1.num1);
System.out.println(staticField2.num1);
staticField1.num2 = 150;
staticField2.num2 = 1500;
System.out.println(staticField1.num2);
System.out.println(staticField2.num2);
}
}
class StaticField {
int num1 = 10;
static int num2 = 15;
}
//출력값
100
1000
1500
1500보시는 것처럼 StaticField 클래스에 인스턴스 필드(num1)와 정적 필드(num2)를 각각 선언하고, 대조를 위해 staticField1와 staticField2 객체를 생성했습니다.
num1의 경우에는 각각의 변수가 고유성을 가지기 때문에 100과 1000으로 따로 출력되는 반면에, num2의 경우는 앞서 배웠던 것처럼 값 공유가 일어나 1500이 출력값으로 두 번 반복되고 있습니다.
이처럼 static 키워드를 사용하면 모든 인스턴스에 공통적으로 적용되는 값을 공유할 수 있습니다.
결론적으로 static 키워드는 클래스의 멤버 앞에 붙일 수 있습니다. 정적 멤버의 가장 큰 특징은 인스턴스를 따로 생성하지 않아도 클래스명만으로도 변수나 메서드 호출이 가능하다는 점이며, 이는 메모리의 저장위치와 관련이 있다는 사실을 알 수 있었습니다.
메서드(Method)
이제 필드와 더불어 클래스의 중요한 구성 요소인 메서드에 대한 내용을 살펴보도록 하겠습니다.
메서드는 “특정 작업을 수행하는 일련의 명령문들의 집합"을 의미하며, 앞서 본 것처럼 클래스의 기능에 해당하는 내용들을 담당합니다. 앞의 자동차의 예시에서 시동걸기, 가속하기, 정지 등이 메서드로 정의되었습니다.
메서드는 다시 크게 머리에 해당하는 메서드 시그니처(method signature)와 몸통에 해당하는 메서드 바디(method body)로 구분할 수 있습니다.
아래 코드 예시를 통해서 좀 더 자세히 알아보도록 하겠습니다.
자바제어자 반환타입 메서드명(매개 변수) { // 메서드 시그니처
메서드 내용 // 메서드 바디
}
위의 예제는 메서드의 시그니처와 바디가 각각 어떻게 구성되어 하나의 메서드를 완성하는 지를 잘 보여주고 있습니다.
먼저 머리에 해당하는 메서드 시그니처를 살펴보면 자바 제어자, 반환타입, 메서드명, 그리고 매개 변수로 이뤄져있다는 사실을 알 수 있습니다.
뒤에서 배우게 될 자바 제어자에 대한 부분을 잠시 생략하고 보면, 메서드의 시그니처는 순서대로 해당 메서드가 어떤 타입을 반환하는 가(반환 타입), 메서드 이름이 무엇(메서드명)이며 해당 작업을 수행하기 위해서 어떤 재료들이 필요한지(매개 변수)에 대한 정보를 포함하고 있습니다.
다음으로 메서드의 바디는 괄호({}) 안에 해당 메서드가 호출되었을 때 수행되어야하는 일련의 작업들을 표시하게 됩니다. 참고로 메서드명은 관례적으로 소문자로 표시합니다.
public static int add(int x, int y) { // 메서드 시그니처
int result = x + y; // 메서드 바디
return result;
}
위의 예시는 앞서 봤었던 내용이 어떻게 실제 코딩에 적용될 수 있는 지 잘 보여주고 있습니다.
이후 학습하게 될 public 접근 제어자를 생략하고 잠시 설명해보자면, 메서드명이 add 인 메서드이며 int 타입 2개의 값(x 와 y )을 받아 더한다음 int 타입의 결과값을 반환하는 메서드라 정리할 수 있습니다.
만약 메서드의 반환타입이 void가 아닌 경우에는 메서드 바디({} )안에 반드시 return 문이 존재해야 합니다. 리턴문은 작업을 수행한 결과값을 호출한 메서드로 전달합니다. 여기서 결과값은 반드시 반환타입과 일치하거나 적어도 자동 형변환이 가능한 것이어야 합니다.
다른 예시들도 한번 볼까요?
void printHello() { // 반환타입이 void인 메서드
System.out.println("hello!");
}
이 예시의 printHello 메서드는 반환 타입이 void, 즉 반환 값이 없는 메서드를 의미합니다. 따라서 printHello 메서드는 호출되면 그저 hello! 라는 내용을 출력하고 종료됩니다.
int getNumSeven() { // 매개변수가 없는 메서드
return 7;
}
getNumSeven 메서드는 int 타입의 결과값을 반환하는 매개변수가 없는 메서드입니다. 해당 메서드가 호출되면 그냥 숫자 7을 반환하면 되기 때문에 따로 매개변수가 필요하지 않습니다.
Double multiply(int x, double y) { // 매개변수가 있는 메서드
double result = x * y;
return result;
}
multiply 메서드는 매개변수 x와 y를 전달받아 반환 타입이 double인 result를 반환하는 매개변수가 있는 메서드입니다(앞서 자바 기초 유닛에서 배웠던 것처럼 int와 double형을 산술 연산하면 범위가 더 큰 타입으로 자동으로 형 변환이 이루어집니다.).
메서드의 호출
메서드를 아무리 잘 정의하더라도 실제로 호출되지 않으면 너무 당연하게도 아무 일도 일어나지 않습니다.
메서드도 클래스의 멤버이므로 클래스 외부에서 메서드를 사용하기 위해서는 먼저 인스턴스를 생성해야합니다. 인스턴스를 생성한 후에 앞서 보았던 것처럼 포인트 연산자(.)를 통해 메서드를 호출할 수 있습니다.
반면, 클래스 내부에 있는 메서드끼리는 따로 객체를 생성하지 않고도 서로를 호출할 수 있습니다.
메서드를 호출하는 기본적인 방법은 다음과 같습니다.
메서드이름(매개변수1, 매개변수2, ...); // 메서드 호출방법. 매개 변수가 없을 수도 있음.
printHello(); // 위의 코드 예제 호출
getNumSeven();
multiply(4, 4.0);
//출력값
hello!
7
16.0위의 코드 예제는 앞서 살펴본 메서드들을 호출한 경우를 보여줍니다. 각각 리턴 타입에 맞는 결과값을 바르게 반환하고 있습니다.
메서드 호출 시 괄호() 안에 넣어주는 입력 값을 우리는 ‘인자(argument)’라고 하는데, 인자의 개수와 순서는 반드시 메서드를 정의할 때 선언된 매개변수와 일치되어야 합니다. 그렇지 않은 경우 실행 에러가 발생합니다. 인자의 타입 또한 매개변수의 그것과 일치하거나 자동 형변환이 가능한 것이어야 합니다.
메서드 오버로딩(Method Overloading)
매서드 오버로딩이란 하나의 클래스 안에 같은 이름의 메서드를 여러 개 정의하는 것을 의미합니다. 영어로 “overload”의 사전적 의미가 ‘과적하다/ 부담을 지우다’라는 점을 생각해보면 좀 더 이해하기 쉽습니다.
보통 하나의 메서드에 하나의 기능만을 구현해야하는데, 같은 이름의 메서드를 여러 기능을 구현하기 때문에 오버로딩이란 용어를 사용한 것이라 생각해볼 수 있습니다.

메서드 오버로딩을 제대로 이해하기 위해서는 먼저 메서드 시그니처(method signature)에 대한 개념 이해가 먼저 선행되어야 합니다.
앞서 봤듯이, 메서드 시그니처는 메서드명과 매개변수의 타입을 의미하는데 “서명"을 의미하는 시그니처라는 단어에서도 유추할 수 있듯이 각 메서드를 구분하는 용도로 사용합니다.
이것은 메서드의 이름 또는 매개변수의 타입이 다르면 다른 메서드라고 인식하는 자바 가상머신의 기능과 관계가 있습니다.
public class Overloading {
public static void main(String[] args) {
Shape s = new Shape(); // 객체 생성
s.area(); // 메서드 호출
s.area(5);
s.area(10,10);
s.area(6.0, 12.0);
}
}
class Shape {
public void area() { // 메서드 오버로딩. 같은 이름의 메서드 4개.
System.out.println("넓이");
}
public void area(int r) {
System.out.println("원 넓이 = " + 3.14 * r * r);
}
public void area(int w, int l) {
System.out.println("직사각형 넓이 = " + w * l);
}
public void area(double b, double h) {
System.out.println("삼각형 넓이 = " + 0.5 * b * h);
}
}
//출력값
넓이
원 넓이 = 78.5
직사각형 넓이 = 100
삼각형 넓이 = 36.0
위의 예시를 보면, Shape 클래스 안에 있는 모든 메서드들이 area()라는 메서드명을 가지고 있음에도 불구하고 각기 다른 출력값을 리턴하는 것을 확인하실 수 있습니다.
오버로딩의 조건을 정리하면 다음과 같습니다.
- 메서드를 오버로딩하려면
- 메서드의 이름이 같아야 합니다.
- 매개변수의 개수 또는 타입이 달라야 합니다.
참고로 반환 타입은 오버로딩이 성립하는 데에 영향을 주지 못합니다.
다른 말로 표현하면, 다른 반환 타입을 지정했다고해서 가상 머신은 다른 메서드라 인식하지 못합니다.
그렇다면 오버로딩의 장점은 무엇일까요?
가장 큰 장점은 하나의 메서드로 여러 경우의 수를 해결할 수 있다는 것입니다.
오버로딩의 대표적인 예시로 println() 메서드가 있습니다. 지금까지 우리가 println() 메서드를 사용했을 때 아무 값이나 괄호()안에 인자로 넣어서 사용하는데 문제가 없었지만, 사실 그 내부를 살펴보면 매개변수의 타입에 따라서 호출되는 println 메서드가 달라진다는 사실을 알 수 있습니다.
만약에 오버로딩이 지원되지 않았다면, 하나하나 일일이 메서드를 정의해줘야하는 번거로움이 발생했을 것입니다. 오버로딩을 통해서 같은 기능을 하는 메서드의 이름을 계속 반복적으로 지어주지 않아도 되고, 이름만 보고도 기능을 쉽게 예측할 수 있습니다.