코드스테이츠 2주차 - 객체지향 프로그래밍 심화(상속과 캡슐화)
상속
자바 언어에서 상속이란 기존의 클래스를 재활용하여 새로운 클래스를 작성하는 자바의 문법 요소를 의미합니다.
가장 단순한 형태를 생각해보면, 두 클래스를 상위 클래스와 하위 클래스로 나누어 상위 클래스의 멤버(필드, 메서드, 이너 클래스)를 하위 클래스와 공유하는 것을 의미합니다.
여기서 우리는 이 두 클래스를 서로 상속 관계 있다고 하며, 하위 클래스는 상위 클래스가 가진 모든 멤버를 상속받게 됩니다.
따라서 하위 클래스의 멤버 개수는 언제나 상위 클래스의 그것과 비교했을 때 같거나 많습니다. 경우에 따라 이러한 상위 클래스-하위 클래스의 관계를 조상-자손 관계로 표현하기도 하는데, 상속의 실제적인 내용을 생각했을 때 조상-자손 관계보다는 상위-하위 클래스로 표현하는 것이 보다 바람직한 표현 방식입니다.
또한, "~클래스로부터 상속받았다"라는 표현보다는 "~클래스로부터 확장되었다"는 표현이 그 역할과 기능을 생각했을 때 더 적절한 표현입니다. 뒤에서 더 자세히 배우겠지만, 두 클래스 간 상속 관계를 설정할 때 사용하는 extends 키워드 자체가 "확장하다"라는 의미를 가지고 있다는 점에 유의할 필요가 있습니다.
상속에 대한 이해를 좀 더 돕기위해 다음의 간단한 예시를 하나 보겠습니다.
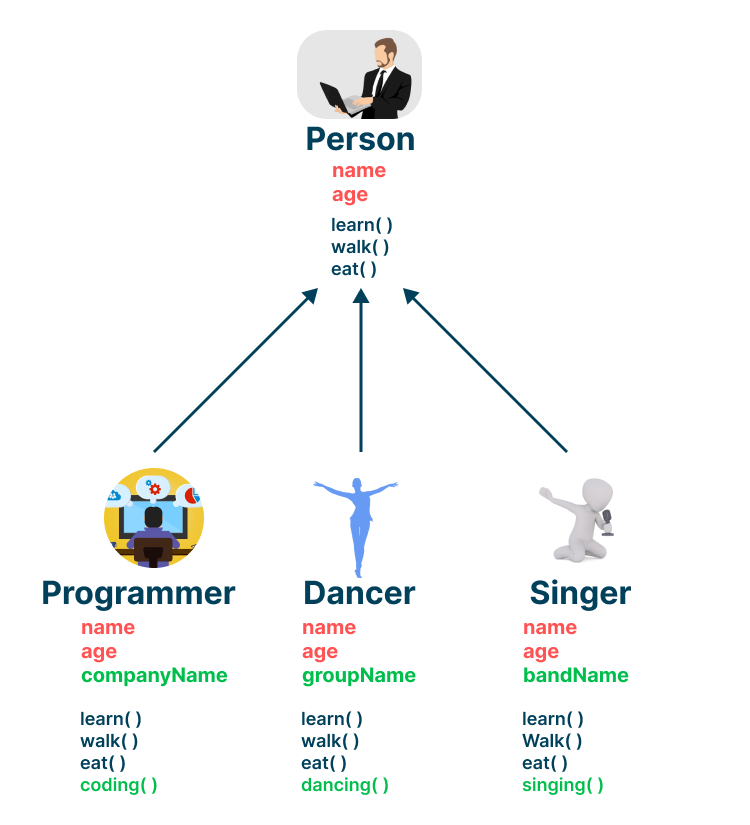
상속을 통해 클래스를 작성하면 앞선 예제에서 확인할 수 있었던 것처럼 코드를 재사용하여 보다 적은 양의 코드로 새로운 클래스를 작성할 수 있어 코드의 중복을 제거할 수 있습니다.
더 나아가, 상속은 다형적 표현이 가능하다는 장점이 있습니다.
다시 위의 예시로 예를 들면, ‘프로그래머는 프로그래머이다'라는 문장은 참입니다. 그와 동시에 ‘프로그래머는 사람이다' 또한 참입니다. 즉 하나의 객체가 여러 모양으로 표현될 수 있다는 것을 우리는 다형성이라 말합니다.
코드 예제
이제 코드를 통해서 앞서 설명한 상속의 개념에 대해 더 알아봅시다.
자바에서 상속을 구현하는 방법은 아주 간단합니다. 클래스를 상속할 때에는 extends 키워드를 사용하며, 클래스명 다음에 extends 상위 클래스명을 사용하여 정의합니다.
다음의 코드예제를 한번 볼까요?
class Person {
String name;
int age;
void learn(){
System.out.println("공부를 합니다.");
};
void walk(){
System.out.println("걷습니다.");
};
void eat(){
System.out.println("밥을 먹습니다.");
};
}
class Programmer extends Person { // Person 클래스로부터 상속. extends 키워드 사용
String companyName;
void coding(){
System.out.println("코딩을 합니다.");
};
}
class Dancer extends Person { // Person 클래스로부터 상속
String groupName;
void dancing(){
System.out.println("춤을 춥니다.");
};
}
class Singer extends Person { // Person 클래스로부터 상속
String bandName;
void singing(){
System.out.println("노래합니다.");
};
void playGuitar(){
System.out.println("기타를 칩니다.");
};
}
public class HelloJava {
public static void main(String[] args){
//Person 객체 생성
Person p = new Person();
p.name = "김코딩";
p.age = 24;
p.learn();
p.eat();
p.walk();
System.out.println(p.name);
//Programmer 객체 생성
Programmer pg = new Programmer();
pg.name = "박해커";
pg.age = 26;
pg.learn(); // Persons 클래스에서 상속받아 사용 가능
pg.coding(); // Programmer의 개별 기능
System.out.println(pg.name);
}
}
//출력값
공부를 합니다.
밥을 먹습니다.
걷습니다.
김코딩
공부를 합니다.
코딩을 합니다.
박해커위의 코드는 앞서 상속 개념을 설명하면서 들었던 예시를 코드로 표현한 것입니다.
보시는 것처럼 Person 클래스로부터 Programmer, Dancer, Singer 클래스가 확장되어 Person 클래스에 있는 속성과 기능들을 사용할 수 있는 것을 확인할 수 있습니다.
또한 각각의 클래스의 개별적인 속성과 기능들은 객체 생성 이후 개별적으로 정의해주고 있습니다.
만약 상속이 없었더라면 객체 하나하나 속성과 기능들을 모두 선언해주어야 했을 것이고, 그 경우 계속해서 같은 코드를 중복해야하는 번거로운 상황을 초래할 것입니다.
마지막으로 언급하고 싶은 내용은 자바의 객체지향 프로그래밍에서는 단일 상속(single inheritance)만을 허용한다는 것입니다. 다른 말로, 다중 상속은 허용되지 않습니다.
이는 C++ 등 다른 객체지향언어와 구분되는 자바 객체지향 프로그래밍의 한 특징이기도 합니다. 다만 자바에서도 앞서 언급했던 인터페이스(interface)라는 문법 요소를 통해 다중 상속과 비슷한 효과를 낼 수 있는 방법이 존재합니다.
포함 관계
앞서 우리는 상속을 통한 클래스 간의 관계 설정에 대한 내용을 학습했습니다.
이번 챕터에서는 상속과 함께 알아두면 유용한 포함 관계에 대한 내용을 살펴볼 것입니다.
포함(composite)은 상속처럼 클래스를 재사용할 수 있는 방법으로, 클래스의 멤버로 다른 클래스 타입의 참조변수를 선언하는 것을 의미합니다.
public class Employee {
int id;
String name;
Address address;
public Employee(int id, String name, Address address) {
this.id = id;
this.name = name;
this.address = address;
}
void showInfo() {
System.out.println(id + " " + name);
System.out.println(address.city+ " " + address.country);
}
public static void main(String[] args) {
Address address1 = new Address("서울", "한국");
Address address2 = new Address("도쿄", "일본");
Employee e = new Employee(1, "김코딩", address1);
Employee e2 = new Employee(2, "박해커", address2);
e.showInfo();
e2.showInfo();
}
}
class Address {
String city, country;
public Address(String city, String country) {
this.city = city;
this.country = country;
}
}
// 출력값
1 김코딩
서울 한국
2 박해커
도쿄 일본위 예시를 보면, 한 회사의 근로자(Employee)를 표현하기 위한 Employee 클래스의 멤버 변수로 근로자가 사는 개략적인 주소를 나타내는 Address 클래스가 정의되어 있습니다.
원래라면 Address 클래스에 포함되어 있는 인스턴스 변수 city와 country를 각각 Employee 클래스의 변수로 정의해주어야 하지만, Address 클래스로 해당 변수들을 묶어준다음 Employee 클래스 안에 참조변수를 선언하는 방법으로 코드의 중복을 없애고 포함관계로 재사용하고 있습니다.
사실 객체지향 프로그래밍에서 상속보다는 포함 관계를 사용하는 경우가 더 많고 대다수라 할 수 있습니다.
그렇다면 클래스 간의 관계를 설정하는 데 있어서 상속관계를 맺어 줄 것 인지 포함 관계를 맺어 줄 것인지를 어떤 기준으로 판별할 수 있을까요?
가장 손쉬운 방법은 클래스 간의 관계가 ‘~은 ~이다(IS-A)’ 관계인지 ~은 ~을 가지고 있다(HAS-A) 관계인지 문장을 만들어 생각해보는 것입니다.
위의 예시로 예를 들어보면, Employee는 Address이다. 라는 문장은 성립하지 않는 반면, Employee는 Address를 가지고 있다. 는 어색하지 않은 올바른 문장임을 알 수 있습니다. 따라서 이 경우에는 상속보다는 포함관계가 적합합니다.
반면 Car 클래스와 SportCar라는 클래스가 있다고 할 때, SportsCars는 Car를 가지고 있다. 라는 문장보다 SportsCar는 Car이다. 라는 문장이 훨씬 더 자연스럽습니다. 따라서 이 경우에는 Car를 상위클래스로 하는 상속관계를 맺어주는 것이 더 적합하다고 할 수 있습니다.
메서드 오버라이딩
메서드 오버라이딩(Method Overriding)은 상위 클래스로부터 상속받은 메서드와 동일한 이름의 메서드를 재정의하는 것을 의미합니다.
영단어 Override의 사전적 의미가 "~위에 덮어쓰다"를 의미한다는 것을 생각해보면서 우리가 컴퓨터를 사용할 때 동일한 위치에 동일한 파일을 저장하고자 할 때 주로 사용하는 덮어쓰기를 연상해보면 좀 더 쉽게 이해할 수 있습니다.
간단한 예시를 통해 살펴보도록 하겠습니다.
public class Main {
public static void main(String[] args) {
Bike bike = new Bike();
Car car = new Car();
MotorBike motorBike = new MotorBike();
bike.run();
car.run();
motorBike.run();
}
}
class Vehicle {
void run() {
System.out.println("Vehicle is running");
}
}
class Bike extends Vehicle {
void run() {
System.out.println("Bike is running");
}
}
class Car extends Vehicle {
void run() {
System.out.println("Car is running");
}
}
class MotorBike extends Vehicle {
void run() {
System.out.println("MotorBike is running");
}
}
// 출력값
Bike is running
Car is running
MotorBike is running위 예시에서, Vehicle 클래스에 run() 메서드가 정의되어 있으며, Bike, Car, MotorBike 클래스에서 run() 메서드를 재정의함으로서 Vehicle 클래스의 run() 메서드를 오버라이딩하고 있습니다.
따라서 Bike, Car, MotorBike의 인스턴스를 통해 run() 메서드를 호출하면 Vehicle의 run()이 아닌, Bike, Car, MotorBike의 run()이 호출됩니다.
이처럼 메서드 오버라이딩은 상위 클래스에 정의된 메서드를 하위 클래스에서 메서드의 동작을 하위 클래스에 맞게 변경하고자 할 때 사용합니다.
상위 클래스의 메서드를 오버라이딩하려면 다음의 세 가지 조건을 반드시 만족시켜야 합니다.
이 조건들 중 2번의 접근제어자와 3번의 예외에 대한 부분은 아직 배우지 않았으니, 지금은 일단 가볍게 읽어주세요.
1. 메서드의 선언부(메서드 이름, 매개변수, 반환타입)이 상위클래스의 그것과 완전히 일치해야한다.
2. 접근 제어자의 범위가 상위 클래스의 메서드보다 같거나 넓어야 한다.
3. 예외는 상위 클래스의 메서드보다 많이 선언할 수 없다.
super 키워드와 super()
앞서 우리는 객체프로그래밍 기초 유닛에서 this 키워드와 this() 메서드를 학습했습니다. 그리고 이 둘의 생김새는 유사하지만 매우 다른 용도로 사용된다는 점을 이해할 수 있었습니다.
배웠던 내용을 한번 더 정리해보면, this는 자기 객체를 가리키는 참조 변수명으로 메서드 내에서 멤버변수와 지역 변수의 이름이 같을 때 구분하기 위한 용도로 사용되며 생략 시 컴파일러가 자동으로 추가해준다고 했습니다.
반면 this() 메서드는 같은 클래스의 다른 생성자를 호출하는데 사용되며 생성자 내에서만 사용가능하고 항상 첫 줄에 위치해야한다고 배웠습니다.
한마디로 정리하면 this는 자신의 객체, this() 메서드는 자신의 생성자 호출을 의미합니다.
이번 챕터에서 배울 super 키워드와 super() 메서드도 이와 비슷하다고 할 수 있습니다. super 키워드는 상위 클래스의 객체, super()는 상위 클래스의 생성자를 호출하는 것을 의미합니다.
공통적으로 모두 상위 클래스의 존재를 상정하며 상속 관계를 전제로 합니다. 그럼 이제 하나씩 살펴보도록 하겠습니다.
먼저 super 키워드를 아래의 예시를 통해 알아보도록 합시다.
public class Example {
public static void main(String[] args) {
SubClass subClassInstance = new SubClass();
subClassInstance.callNum();
}
}
class SuperClass {
int count = 20; // super.count
}
class SubClass extends SuperClass {
int count = 15; // this.count
void callNum() {
System.out.println("count = " + count);
System.out.println("this.count = " + this.count);
System.out.println("super.count = " + super.count);
}
}
// 출력값
count = 15
count = 15
count = 20
위에 예제에서 Lower 클래스는 Upper 클래스로부터 변수 count를 상속받는데, 공교롭게도 자신의 인스턴스 변수 count와 이름이 같아 둘을 구분할 방법이 필요합니다.
이런 경우, 두 개의 같은 이름의 변수를 구분하기 위한 방법이 바로 super 키워드입니다.
만약 super 키워드를 붙이지 않는다면, 자바 컴파일러는 해당 객체는 자신이 속한 인스턴스 객체의 멤버를 먼저 참조합니다.
반면 경우에 따라서 상위 클래스의 변수를 참조해야할 경우가 종종 있는데 그 경우 super 키워드를 사용하면 부모의 객체의 멤버 값을 참고할 수 있습니다.
즉, 상위 클래스의 멤버와 자신의 멤버를 구별하는 데 사용된다는 점을 제외한다면 this와 super는 기본적으로 같은 것이라 말할 수 있습니다.
위의 예시에서 첫 번째 count는 자기에게서 가장 가까운 count 변수, 즉 15를 가리킵니다.
두 번째 카운트 또한 자신이 호출된 객체의 인스턴스 변수를 가리키기 때문에 15를 출력합니다.
마지막으로 super 키워드를 사용하여 호출한 count는 앞서 설명드렸던 것처럼 상위 클래스의 변수를 참조하여 숫자 20을 출력합니다.
다음으로 super() 메서드를 살펴볼까요?
앞서 간략하게 설명한 것처럼, super()도 this() 메서드처럼 생성자를 호출할 때 사용합니다.
그리고 마찬가지로, this()와의 차이는 this()가 같은 클래스의 다른 생성자를 호출하는데 사용하는 반해, super()는 상위 클래스의 생성자를 호출하는데 사용된다는 것입니다.
다음의 예시를 통해 좀 더 알아보겠습니다.
public class Test {
public static void main(String[] args) {
Student s = new Student();
}
}
class Human {
Human() {
System.out.println("휴먼 클래스 생성자");
}
}
class Student extends Human { // Human 클래스로부터 상속
Student() {
super(); // Human 클래스의 생성자 호출
System.out.println("학생 클래스 생성자");
}
}
// 출력값
휴먼 클래스 생성자
학생 클래스 생성자
Human 클래스를 확장하여 Student 클래스를 생성하고, Student 생성자를 통해 상위 클래스 Human 클래스의 생성자를 호출하고 있습니다.
super() 메서드 또한 this()와 마찬가지로 생성자 안에서만 사용가능하고, 반드시 첫 줄에 와야 합니다.
예제에서 super() 메서드는 Student 클래스 내부에서 호출되고 있고 상위 클래스 Human의 생성자를 호출하고 있습니다. 그리고 출력값으로 “휴먼 클래스 생성자”와 "학생 클래스 생성자"가 순차적으로 출력됩니다.
여기서 기억해야하는 가장 중요한 사실은 모든 생성자의 첫 줄에는 반드시 this() 또는 super()가 선언되어야 한다는 것입니다.
만약 super()가 없는 경우에는 컴파일러가 생성자의 첫 줄에 자동으로 super()를 삽입합니다.
이때 상위클래스에 기본생성자가 없으면 에러가 발생하게 됩니다.
따라서 클래스를 만들 때는 자동으로 기본 생성자를 생성하는 것을 습관화하는 것이 좋습니다.
클래스의 정점, Object 클래스
Object 클래스는 자바의 클래스 상속계층도에서 최상위에 위치한 상위클래스입니다. 따라서 자바의 모든 클래스는 Object 클래스로부터 확장된다는 명제는 항상 참입니다.
실제로 자바 컴파일러는 컴파일 과정에서 다른 클래스로부터 아무런 상속을 받지 않는 클래스에 자동적으로 extends Object를 추가하여 Object 클래스를 상속받도록 합니다.
class ParentEx { // 컴파일러가 "extends Object" 자동 추가
}
class ChildEx extends ParentEx {
}
위의 예시에서, ParentEx 클래스를 상속받아 ChildEx 클래스를 만들었을 때 상위클래스 ParentEx는 아무것도 상속하고 있지 않기에 컴파일러는 extends Object를 삽입하는 것입니다.
앞서 설명한 것처럼 Object 클래스는 자바 클래스의 상속계층도에 가장 위에 위치하기 때문에 Object 클래스의 멤버들을 자동으로 상속받아 사용할 수 있습니다.
Object 클래스에서 확장되어 사용 메서드들은 매우 많지만, 대표적인 메서드 몇 가지만 소개하겠습니다.
지금 당장 각 메서드들의 역할과 기능을 이해하지 못해도 괜찮습니다. 지금은 클래스 계층도의 최상위에 Object 클래스가 있다는 것, 그리고 이에 따라 아래와 같은 메서드들을 따로 정의하지 않고도 사용가능하다는 점만 기억해주세요.
더 추가적인 내용들은 이후 학습을 진행하시면서 차차 자연스럽게 이해할 수 있게 될 것입니다.
아래에 Object 클래스의 대표적인 메서드를 나열해두었습니다. 해당 메서드들을 여러분이 지금 당장 외워야 하는 것은 아니니, "이런 것들이 있구나" 정도로만 훑어보시고 넘어가시기 바랍니다.
| 메서드명 | 반환 타입 | 주요 내용 |
| toString() | String | 객체 정보를 문자열로 출력 |
| equals(Object obj) | boolean | 등가 비교 연산(==)과 동일하게 스택 메모리값을 비교 |
| hashCode() | int | 객체의 위치정보 관련. Hashtable 또는 HashMap에서 동일 객체여부 판단 |
| wait() | void | 현재 쓰레드 일시정지 |
| notify() | void | 일시정지 중인 쓰레드 재동작 |
캡슐화
캡슐화란 특정 객체 안에 관련된 속성과 기능을 하나의 캡슐(capsule)로 만들어 데이터를 외부로부터 보호하는 것을 말합니다.
이렇게 캡슐화를 해야하는 이유로 크게 두 가지 목적이 있습니다. 첫 째는 데이터 보호의 목적이고, 두 번째로 내부적으로만 사용되는 데이터에 대한 불필요한 외부 노출을 방지하기 위함입니다.
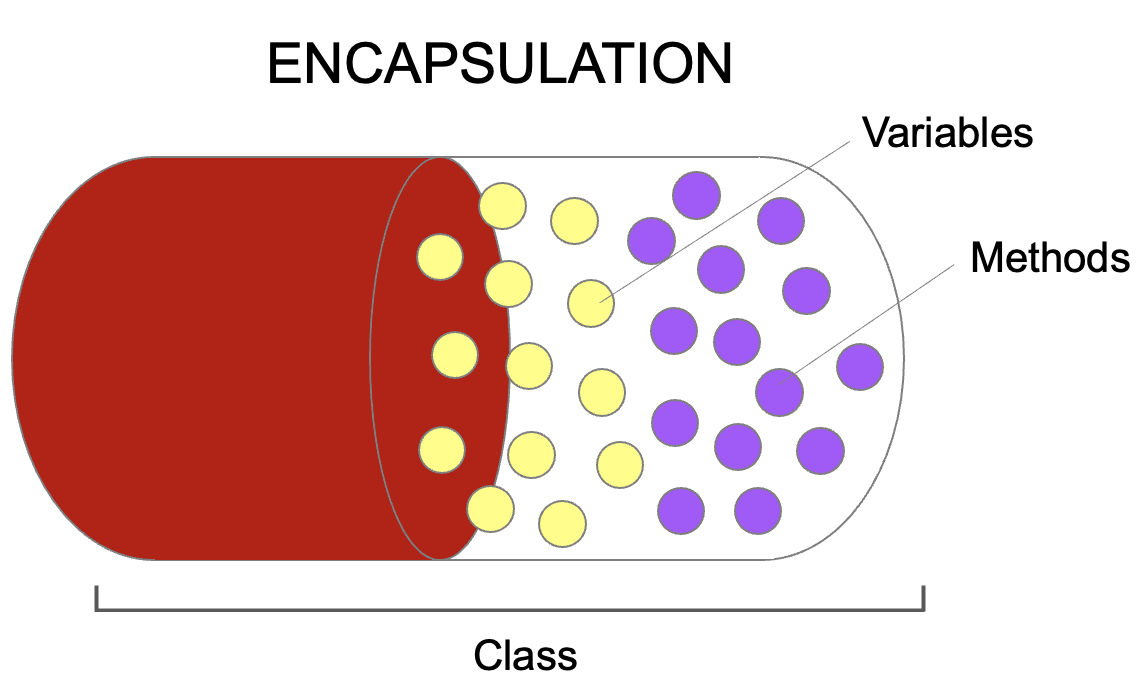
정리하면, 캡슐화의 가장 큰 장점은 정보 은닉(data hiding)에 있다고 정리할 수 있습니다.
즉, 외부로부터 객체의 속성과 기능이 함부로 변경되지 못하게 막고, 데이터가 변경되더라도 다른 객체에 영향을 주지 않기에 독립성을 확보할 수 있습니다.
더 나아가 유지보수와 코드 확장 시에도 오류의 범위를 최소화할 수 있어서 효과적으로 코드를 유지보수하기에 용이합니다.
패키지
패키지(package)란 특정한 목적을 공유하는 클래스와 인터페이스의 묶음을 의미합니다.
인터페이스에 대한 내용은 곧 다가오는 챕터에서 학습하기 때문에, 지금은 패키지가 비슷한 목적을 가진 클래스와 인터페이스의 묶음으로 이뤄져있다라는 사실만 기억하고 넘어가주세요.
클래스를 정의할 때 관련있는 속성과 기능을 묶어 데이터들을 효율적으로 관리할 수 있었듯, 패키지는 클래스들을 그룹 단위로 묶어 효과적으로 관리하기 위한 목적을 가지고 있습니다.
우리가 컴퓨터를 사용할 때 폴더를 만들어 그 폴더와 관련된 파일들을 관리하는 것과 유사하다고 할 수 있습니다.
자바에서 패키지는 물리적인 하나의 디렉토리(directory)이고, 하나의 패키지에 속한 클래스나 인터페이스 파일은 모두 해당 패키지에 속해있습니다.
더 나아가, 이 디렉토리는 하나의 계층구조를 가지고 있는데, 계층 구조 간 구분은 점(.)으로 표현됩니다.
마지막으로, 패키지가 있는 경우 소스 코드의 첫 번째 줄에 반드시 package 패키지명이 표시되어야 하고, 만약 패키지 선언이 없으면 이름없는 패키지에 속하게 됩니다.
아래의 예시를 한번 확인해봅시다.
// 패키지를 생성했을 때
package practicepack.test; // 패키지 구문 포함. 패키지가 없다면 구문 필요없음
public class PackageEx {
}자바에 기본적으로 포함되어있는 대표적인 패키지로 자바의 기본 클래스들을 모아 놓은 java.lang, 확장 클래스를 묶어 놓은 java.util, 자바의 입출력과 관련된 클래스를 묶어놓은 java.io와 java.nio 등이 있습니다.
예를 들면, 우리가 주로 사용하는 String 클래스의 실제 이름은 java.lang.String인데, 여기서 java.lang은 패키지명을 나타내고 점(.)을 사용하여 디렉터리 계층구조를 나타내고 있습니다.
이렇게 패키지로 클래스를 묶는 것의 또 하나의 장점은 클래스의 충돌을 방지해주는 기능에 있습니다. 예를 들면, 같은 이름의 클래스를 가지고 있더라고 각각 다른 패키지에 소속되어 있다면 이름명으로 인한 충돌이 발생하지 않습니다.
규모가 큰 프로젝트에서 협업시 클래스명 중복으로 인한 충돌이 종종 발생할 수 있는데 패키지를 설정하면 이러한 클래스 간의 충돌을 효과적으로 방지할 수 있습니다.
Import문
import문은 다른 패키지 내의 클래스를 사용하기 위해 사용하며, 일반적으로 패키지 구문과 클래스문 사이에 작성합니다.
예를 들면, import문 없이 다른 패키지의 클래스를 사용하기 위해서는 아래와 같이 매번 패키지명을 붙여 주어야 하는데, import문을 사용하면 사전에 컴파일러에게 소스파일에 사용된 클래스에 대한 정보를 제공하여 이러한 번거로움을 덜어줍니다.
아래의 예시를 통해서 좀 더 알아보겠습니다.
package practicepack.test;
public class ExampleImport {
public int a = 10;
public void print() {
System.out.println("Import문 테스트")
}
}package practicepack.test2; // import문을 사용하지 않는 경우, 다른 패키지 클래스 사용방법
public class PackageImp {
public static void main(String[] args) {
practicepack.test.ExampleImport example = new practicepack.test.ExampleImport();
}
}위의 예시를 보면, import문을 사용하지 않고 다른 패키지의 클래스를 사용하기 위해서 패키지명을 모두 포함시켜서 클래스의 패키지에 대한 정보를 제공해야한다는 사실을 알 수 있습니다.
그렇다면 import문을 사용하면 어떨까요?
import문은 다음과 같이 작성할 수 있습니다.
import 패키지명.클래스명; 또는 import 패키지명.*;먼저 import 키워드를 써주고 패키지명과 패키지명을 생략하고자하는 클래스명을 함께 써주면 됩니다.
만약 같은 패키지에서 여러 클래스가 사용될 때는 import문을 여러번 사용하기보다는 위에 작성된 것처럼 import 패키지명.* 으로 작성하면 해당 패키지의 모든 클래스를 패키지명 없이 사용가능합니다.
그럼 이제 이 방법을 사용해서 위의 예제에 적용해볼까요?
package practicepack.test;
public class ExampleImp {
public int a = 10;
public void print() {
System.out.println("Import문 테스트")
}package practicepack.test2; // import문을 사용하는 경우
import practicepack.test.ExampleImp // import문 작성
public class PackageImp {
public static void main(String[] args) {
ExampleImp x = new ExampleImp(); // 이제 패키지명을 생략 가능참고로 import문은 컴파일 시에 처리가되므로 프로그램의 성능에는 영향을 주지 않습니다.
접근 제어자
제어자(Modifier)
자바 프로그래밍에서 제어자는 클래스, 필드, 메서드, 생성자 등에 부가적인 의미를 부여하는 키워드를 의미합니다.
‘ 파란 하늘', ‘ 붉은 노을'에서 ‘파란'과 ‘붉은'처럼 명사를 꾸며주는 형용사의 역할과 같다고 할 수 있습니다.
자바에서 제어자는 크게 접근 제어자와 기타 제어자로 구분 할 수 있습니다.
| 접근 제어자 | public, protected, (default), private |
| 기타 제어자 | static, final, abstract, native, transient, synchronized 등 |
앞서 언급했듯, 제어자는 클래스, 필드, 메서드, 생성자 등에 주로 사용되며 ‘ 맛있는 빨간 사과'에서 사과를 수식하기 위해 ‘맛있는'과 ‘빨간'이라는 형용사가 두 번 사용된 것처럼 하나의 대상에 대해서 여러 제어자를 사용할 수 있습니다.
하지만, 각 대상에 대해서 접근 제어자는 단 한번만 사용할 수 있습니다.
기타제어자와 관련해서는 static, final, abstract 키워드가 주로 사용되기 때문에 이 세 가지를 중심으로 학습을 먼저 진행하고, 나머지는 차차 필요에 따라 학습해가는 것을 권장드립니다.
접근 제어자(Access Modifier)
이제 자바 객체지향 프로그래밍의 캡슐화를 구현하기 위한 핵심적인 방법으로 접근 제어자를 학습해봅시다.
앞서 설명한대로, 접근 제어자를 사용하면 클래스 외부로의 불필요한 데이터 노출을 방지(data hiding)할 수 있고, 외부로부터 데이터가 임의로 변경되지 않도록 막을 수 있습니다. 이것은 데이터 보호의 측면에서 매우 중요하다고 할 수 있습니다.
자바 접근 제어자로 다음의 4 가지가 있습니다.
| 접근 제어자 | 접근 제한 범위 |
| private | 동일 클래스에서만 접근 가능 |
| default | 동일 패키지 내에서만 접근 가능 |
| protected | 동일 패키지 + 다른 패키지의 하위 클래스에서 접근 가능 |
| public | 접근 제한 없음 |
위의 내용을 접근 제한 범위에 따라서 표현하면, public(접근 제한 없음) > protected(동일 패키지 + 하위클래스) > default(동일 패키지) > private(동일 클래스) 순으로 정리할 수 있습니다.
이중 default의 경우는 아무런 접근 제어자를 붙이지 않는 경우 기본적인 설정을 의미합니다. 즉 변수명 앞에 아무런 접근제어자가 없는 경우에는 자동으로 해당 변수의 접근 제어자는 default가 됩니다.

이제 예시를 통해서 좀 더 자세히 알아보도록 합니다.
package package1; // 패키지명 package1
//파일명: Parent.java
class Test { // Test 클래스의 접근 제어자는 default
public static void main(String[] args) {
Parent p = new Parent();
// System.out.println(p.a); // 동일 클래스가 아니기 때문에 에러발생!
System.out.println(p.b);
System.out.println(p.c);
System.out.println(p.d);
}
}
public class Parent { // Parent 클래스의 접근 제어자는 public
private int a = 1; // a,b,c,d에 각각 private, default, protected, public 접근제어자 지정
int b = 2;
protected int c = 3;
public int d = 4;
public void printEach() { // 동일 클래스이기 때문에 에러발생하지 않음
System.out.println(a);
System.out.println(b);
System.out.println(c);
System.out.println(d);
}
}
// 출력값
2
3
4먼저 동일한 패키지에 속한 경우를 살펴보도록 하겠습니다.
아래 Parent 클래스를 먼저 살펴볼까요?
a,b,c,d 모두 에러 없이 정상적으로 접근 가능함을 확인하실 수 있습니다.
동일한 패키지의 동일한 클래스 내에 있기 때문에 가장 접근 제한이 엄격한 private 변수도 접근이 가능합니다.
반면 위의 Test 클래스에서 객체를 생성하여 접근을 시도했을 때는 private 접근 제어자가 있는 a에는 접근이 불가하여 에러가 발생하는 모습을 확인할 수 있습니다.
package package2; // package2
//파일명 Test2.java
import package1.Parent;
class Child extends package1.Parent { // package1으로부터 Parent 클래스를 상속
public void printEach() {
// System.out.println(a); // 에러 발생!
// System.out.println(b);
System.out.println(c); // 다른 패키지의 하위 클래스
System.out.println(d);
}
}
public class Test2 {
public static void main(String[] args) {
Parent p = new Parent();
// System.out.println(p.a); // public을 제외한 모든 호출 에러!
// System.out.println(p.b);
// System.out.println(p.c);
System.out.println(p.d);
}
}
그렇다면 다른 패키지에 있는 경우는 어떨까요?
먼저 package1의 Parent 클래스로부터 상속을 받아 만들어진 Child 클래스를 살펴보면, 같은 클래스와 같은 패키지 안에 있는 private(a)과 default(b) 접근 제어자를 사용하는 멤버에는 접근이 불가능한 반면, 다른 패키지의 하위 클래스에 접근가능한 protected(c)와 어디서나 접근이 가능한 public(d)에는 접근이 가능하다는 사실을 확인할 수 있습니다.
마지막으로 Test2 클래스는 상속받은 클래스가 아니기 때문에 다시 protected(c)에는 접근이 불가능하고 public(d)에만 접근이 가능합니다.
결론적으로 다시 정리하면, 우리는 접근 제어자를 통해 외부로부터 데이터를 보호하고, 불필요하게 데이터가 노출되는 것을 방지 할 수 있습니다.
getter와 setter 메서드
앞서 우리는 자바에서 데이터 보호와 은닉을 위한 효과적인 방법으로 접근 제어자를 사용한다는 것을 학습했습니다.
그렇다면 객체지향의 캡슐화의 목적을 달성하면서도 데이터의 변경이 필요한 경우는 어떻게 할 수 있을까요?
대표적으로 private 접근제어자가 포함되어 있는 객체의 변수의 데이터 값을 추가하거나 수정하고 싶을 때를 생각해볼 수 있습니다.
이런 경우 우리는 getter와 setter 메서드를 사용할 수 있습니다.
마찬가지로 간단한 예시를 통해 알아보도록 하겠습니다.
public class GetterSetterTest {
public static void main(String[] args) {
Worker w = new Worker();
w.setName("김코딩");
w.setAge(30);
w.setId(5);
String name = w.getName();
System.out.println("근로자의 이름은 " + name);
int age = w.getAge();
System.out.println("근로자의 나이는 " + age);
int id = w.getId();
System.out.println("근로자의 ID는 " + id);
}
}
class Worker {
private String name; // 변수의 은닉화. 외부로부터 접근 불가
private int age;
private int id;
public String getName() { // 멤버변수의 값
return name;
}
public void setName(String name) { // 멤버변수의 값 변경
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
if(age < 1) return;
this.age = age;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
}
// 출력값
근로자의 이름은 김코딩
근로자의 나이는 30
근로자의 ID는 5위의 예제는 자바 객체지향 프로그래밍에서 캡슐화를 통해 데이터를 보호하면서도 어떻게 데이터를 변경할 수 있는 지 잘 보여주고 있습니다.
먼저 setter 메서드는 외부에서 메서드에 접근하여 조건에 맞을 경우 데이터 값을 변경 가능하게 해주고 일반적으로 메서드명에 set-을 붙여서 정의합니다.
예시를 보면 이름 값을 변경하기 위해 setName()이라는 메서드를 사용하고 있음을 확인할 수 있습니다.
한편 getter 메서드는 이렇게 설정한 변수 값을 읽어오는 데 사용하는 메서드입니다.
경우에 따라 객체 외부에서 필드 값을 사용하기에 부적절한 경우가 발생할 수 있는데 이런 경우에 그 값을 가공한 이후에 외부로 전달하는 역할을 하게 됩니다.
위의 예시에서 볼 수 있듯이 get-을 메서드명 앞에 붙여서 사용합니다.
예시를 좀 더 자세히 살펴보면, 먼저 Worker 클래스를 기반으로 객체 인스턴스를 생성해주고 같은 타입을 가지고 있는 참조변수 w에 담았습니다.
다음으로 w의 setter 메서드를 사용하여 이름, 나이, 아이디에 대한 데이터 값을 저장하고, getter 메서드를 통해 해당 데이터 값을 불러와 변수에 담아 출력해주고 있습니다.
이렇게 setter와 getter 메서드를 활용하면 데이터를 효과적으로 보호하면서도 의도하는 값으로 값을 변경하여 캡슐화를 보다 효과적으로 달성할 수 있습니다.