데이터베이스 설계
관계형 데이터베이스
구조화된 데이터는 하나의 테이블로 표현할 수 있습니다. 사전에 정의된 테이블을 relation 이라고도 부르기 때문에, 테이블을 사용하는 데이터베이스를 관계형 데이터베이스(Relational database)라고 합니다.
다음은 관계형 데이터베이스를 학습하면서, 반드시 알고 있어야 하는 키워드입니다.
- 데이터(data): 각 항목에 저장되는 값입니다.
- 테이블(table; 또는 relation) : 사전에 정의된 열의 데이터 타입대로 작성된 데이터가 행으로 축적됩니다.
- 열(column; 또는 field) : 테이블의 한 열을 가리킵니다.
- 레코드(record; 또는 tuple) : 테이블의 한 행에 저장된 데이터입니다.
- 키(key) : 테이블의 각 레코드를 구분할 수 있는 값입니다. 각 레코드마다 고유한 값을 가집니다. 기본키(primary key)와 외래키(foreign key) 등이 있습니다.
관계 종류
테이블과 테이블 사이의 관계는 다음과 같습니다.
- 1:1 관계
- 1:N 관계
- N:N 관계
테이블 스스로 관계를 가질 수도 있습니다.
- self referencing 관계
1:1 관계
하나의 레코드가 다른 테이블의 레코드 한 개와 연결된 경우입니다. 다음과 같이 User 테이블과 Phonebook 테이블이 있다고 가정하겠습니다.
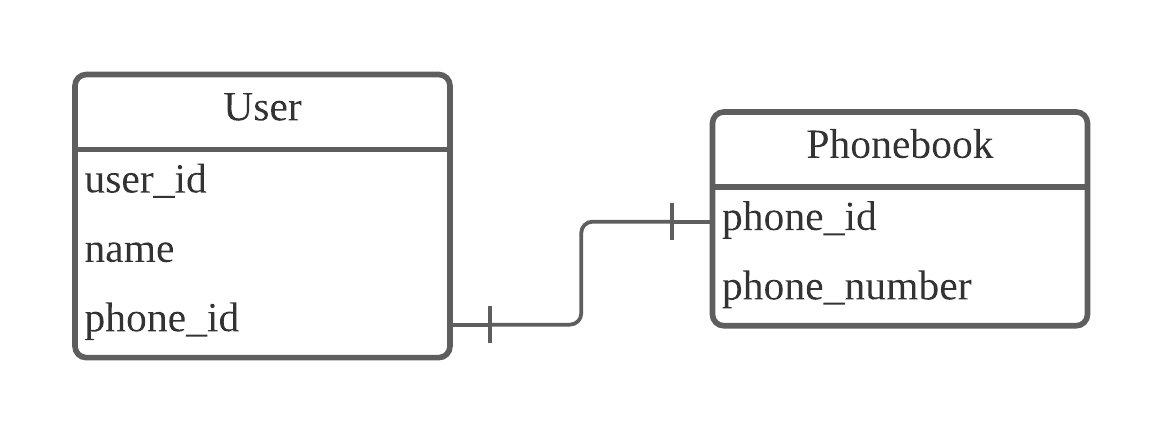
[그림] User table과 Phonebook table의 1:1 관계
User 테이블은 user_id, name, phone_id를 가지고 있습니다. 이 중 phone_id는 외래키(foreign key)로써, Phonebook 테이블의 phone_id와 연결되어 있습니다. Phonebook 테이블은 phone_id와 phone_number를 가지고 있습니다.
각 전화번호가 단 한 명의 유저와 연결되어 있고, 그 반대도 동일하다면, User 테이블과 Phonebook 테이블은 1:1 관계(One-to-one relationship)입니다.
그러나 1:1 관계는 자주 사용하지 않습니다. 1:1로 나타낼 수 있는 관계라면 User 테이블에 phone_id를 대신해 phone_number를 직접 저장하는 게 나을 수 있습니다.
1:N 관계
하나의 레코드가 서로 다른 여러 개의 레코드와 연결된 경우입니다. User 테이블과 Phonebook 테이블의 관계를 다음과 같이 가정하겠습니다.
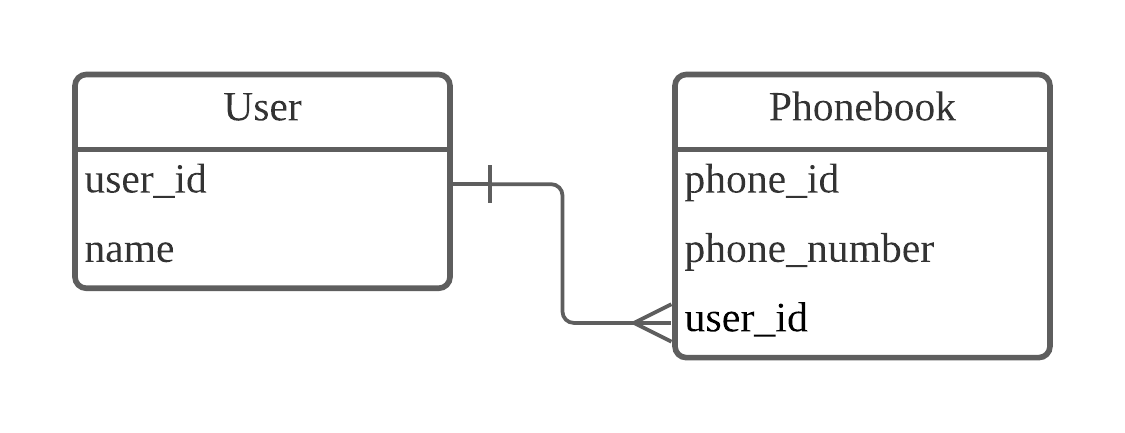
[그림] User table과 Phonebook table의 1:N 관계
이 구조에서는 한 명의 유저가 여러 전화번호를 가질 수 있습니다. 그러나 여러 명의 유저가 하나의 전화번호를 가질 수는 없습니다. 이런 1:N(일대다) 관계는 관계형 데이터베이스에서 가장 많이 사용합니다.
N:N 관계
여러 개의 레코드가 다른 테이블의 여러 개의 레코드와 관계가 있는 경우입니다. N:N(다대다) 관계를 위해 스키마를 디자인할 때에는, Join 테이블을 만들어 관리합니다. 1:N(일대다) 관계와 비슷하지만, 양방향에서 다수의 레코드를 가질 수 있습니다.
다음과 같이 여행 상품을 관리하는 테이블이 있다고 가정하겠습니다. 여러 개의 여행 상품이 있고, 여러 명의 고객이 있습니다. 고객 한 명은 여러 개의 여행 상품을 구매할 수 있고, 여행 상품 하나는 여러 명의 고객이 구매할 수 있습니다.
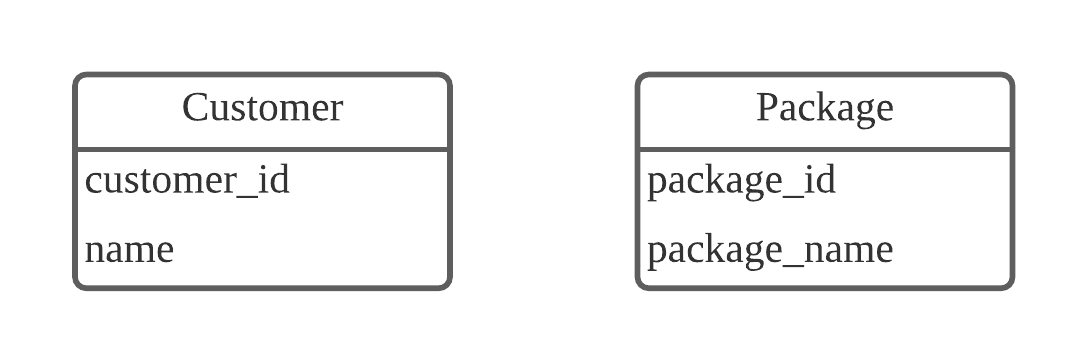
[그림] Customer table과 Package table
이렇게 Customer 테이블과 Package table이 따로 존재한다면, N:N(다대다) 관계를 어떻게 표현할 수 있을까요? 다대다 관계는 두 개의 일대다 관계와 그 모양이 같습니다. 두 개의 테이블과 1:N(일대다) 관계를 형성하는 새로운 테이블로 N:N(다대다) 관계를 나타낼 수 있습니다.
이렇게 다대다 관계를 위한 테이블을 조인 테이블이라고 합니다. N:N(다대다) 관계를 그림으로 나타내면 다음과 같습니다.
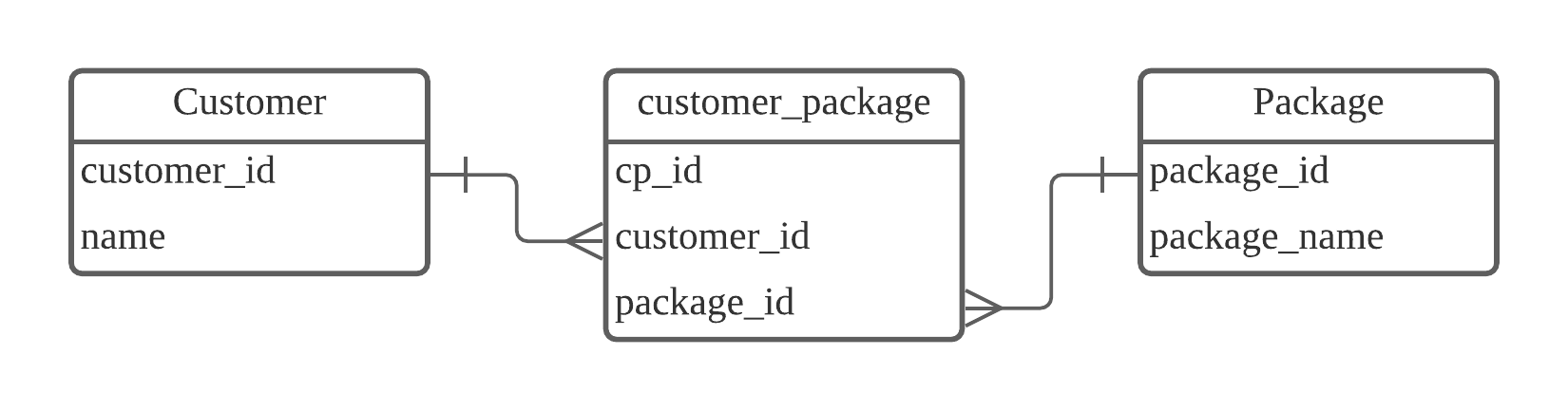
[그림] Customer table과 Package table의 N:N 관계를 위해 customer_package 테이블을 생성
customer_package 테이블에서는 고객 한 명이 여러 개의 여행 상품을 가질 수 있고, 여행 상품 하나가 여러 개의 고객을 가질 수 있습니다.
customer_package 테이블은 customer_id와 package_id를 묶어주는 역할입니다. 이 테이블을 통해 어떤 고객이 몇 개의 여행 상품을 구매했는지 또는, 어떤 여행 상품이 몇 명의 고객을 가지고 있는지 등을 확인할 수 있습니다. 이렇게 조인 테이블을 생성하더라도, 조인 테이블을 위한 기본키(여기서는 cp_id)는 반드시 있어야 합니다.
- 만약 외래키를 리스트 형식으로 관리하는 필드가 있다면, 어떤 문제가 발생할 수 있을까요?
자기 참조 관계(Self Referencing Relationship)
때로는 테이블 내에서도 관계가 필요합니다. 예를 들어 추천인이 누구인지 파악하기 위해 사용할 수 있습니다.
다음과 같이 유저 테이블이 있습니다. user_id는 기본 키(primary key), name은 사용자의 이름, 그리고 recommend_id는 추천인 아이디입니다.
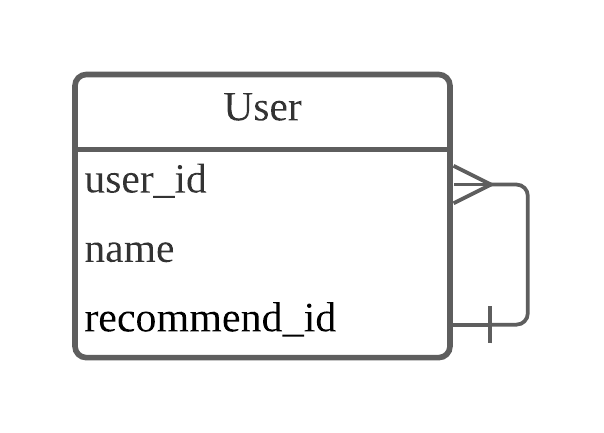
[그림] 자기 참조 관계를 가지는 User table
User 테이블의 recommend_id는 User 테이블의 user_id와 연결되어 있습니다. 한 명의 유저(user_id)는 한 명의 추천인(recommend_id)을 가질 수 있습니다. 그러나 여러 명이 한 명의 유저를 추천인으로 등록할 수 있습니다. 이 관계는 1:N(일대다) 관계와 유사하다고 생각할 수 있습니다. 그러나 일반적으로 일대다 관계는 서로 다른 테이블의 관계를 나타낼 때 표현하는 방법입니다.
SQL More
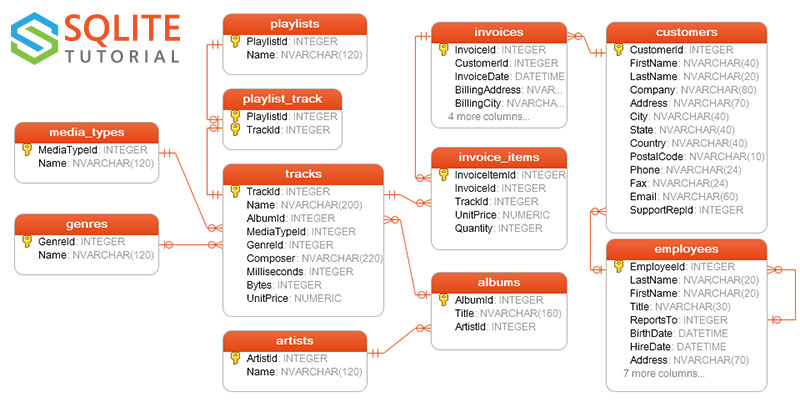
- 이 콘텐츠에서 사용하는 예시는 위 그림의 스키마를 기준으로 설명하였습니다.
소개
SQL에서 사용되는 쿼리에는 유용하게 사용할 수 있는 함수도 많습니다. 또한 SQL에 대해 더 공부한다면, 더 많은 쿼리문이 있다는 사실에 놀랄 겁니다. 이 콘텐츠에서는 그중에서 자주 사용하는 몇 가지를 설명합니다.
SQL 내장함수
집합연산: 레코드를 조회하고 분류한 뒤, 특정 작업을 하는 연산
GROUP BY
데이터를 조회할 때 그룹으로 묶어서 조회합니다. 다음과 같은 쿼리가 있다고 가정하겠습니다.
SELECT * FROM customers;이 쿼리를 주(state)에 따라 그룹으로 묶어 표현할 수 있습니다.
SELECT * FROM customers
GROUP BY State;GROUP BY 쿼리로 간단하게 State에 따라 그룹화할 수 있습니다. 쿼리의 결과를 확인하면, 데이터가 중간에 비어있는 것을 확인할 수 있습니다. 데이터베이스에서 데이터를 불러오는 과정에서 State에 따라 그룹을 지정했지만, 그룹 대한 작업 없이 조회만 했습니다. 그래서 쿼리의 결과로 나타나는 데이터는 각 그룹의 첫 번째 데이터만 표현됩니다.
HAVING
HAVING은 GROUP BY로 조회된 결과를 필터링할 수 있습니다. 다음의 쿼리를 보겠습니다.
SELECT CustomerId, AVG(Total)
FROM invoices
GROUP BY CustomerId
HAVING AVG(Total) > 6.00이 쿼리는 모든 고객의 주문서에서 가격의 평균을 구한 뒤에, 그 평균이 6.00을 넘는 결과만 조회합니다.
이렇게 GROUP BY로 그룹을 지은 결과에 필터를 적용할 때에는 HAVING을 사용할 수 있습니다.
HAVING은 WHERE과는 적용하는 방식이 다릅니다. HAVING은 그룹화한 결과에 대한 필터이고, WHERE는 저장된 레코드를 필터링합니다. 따라서 실제로 그룹화 전에 데이터를 필터해야 한다면, WHERE을 사용합니다.
GROUP BY로 그룹화하는 방법을 학습했습니다. 이어서 그룹에 대해 어떤 작업을 할 수 있는지 확인합니다.
COUNT()
COUNT 함수는 레코드의 개수를 헤아릴 때 사용합니다. COUNT 함수의 사용법은 다음과 같습니다.
SELECT *, COUNT(*) FROM customers
GROUP BY State;위 커맨드를 실제로 실행하면, 각 그룹의 첫 번째 레코드와 각 그룹의 레코드 개수를 집계하여 리턴합니다. 다음과 같이 변경하면, 그룹으로 묶인 결과의 레코드 개수를 확인할 수 있습니다.
SELECT State, COUNT(*) FROM customers
GROUP BY State;SUM()
SUM 함수는 레코드의 합을 리턴합니다. SUM 함수의 사용법은 다음과 같습니다.
SELECT InvoiceId, SUM(UnitPrice)
FROM invoice_items
GROUP BY InvoiceId;위 커맨드는 invoice_items라는 테이블에서 InvoiceId 필드를 기준으로 그룹하고, UnitPrice 필드 값의 합을 구합니다.
AVG()
AVG 함수는 레코드의 평균값을 계산하는 함수입니다. AVG 함수의 사용법은 다음과 같습니다.
SELECT TrackId, AVG(UnitPrice)
FROM invoice_items
GROUP BY TrackId;MAX(), MIN()
MAX 함수와 MIN 함수는 각각 레코드의 최대값과 최소값을 리턴합니다. 이 함수들은 다음과 같이 사용합니다.
SELECT CustomerId, MIN(Total)
FROM invoices
GROUP BY CustomerId위 커맨드에서 MIN을 MAX로 변경하면, 각 고객이 지불한 최대 금액을 리턴합니다.
SELECT 실행 순서
데이터를 조회하는 SELECT 문은 정해진 순서대로 동작합니다. SELECT 문의 실행 순서는 다음과 같습니다.
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT
- ORDER BY
예시와 함께 살펴보겠습니다.
SELECT CustomerId, AVG(Total)
FROM invoices
WHERE CustomerId >= 10
GROUP BY CustomerId
HAVING SUM(Total) >= 30
ORDER BY 2위 쿼리문의 실행 순서는 다음과 같습니다. 1. FROM invoices: invoices 테이블에 접근을 합니다. 2. WHERE CustomerId >= 10: CustomerId 필드가 10 이상인 레코드들을 조회합니다. 3. GROUP BY CustomerId: CustomerId를 기준으로 그룹화합니다. 4. HAVING SUM(Total) >= 30: Total 필드의 총합이 30 이상인 결과들만 필터링합니다. 5. SELECT CustomerId, AVG(Total): 조회된 결과에서 CustomerId 필드와 Total 필드의 평균값을 구합니다. 6. ORDER BY 2: AVG(Total) 필드를 기준으로 오름차순 정렬한 결과를 리턴합니다.
'코드스테이츠 > section2' 카테고리의 다른 글
| [Section2] 이해도 자가 점검 리스트 (0) | 2023.05.30 |
|---|---|
| [Section 2][관계형 데이터베이스] Advanced (0) | 2023.05.30 |
| [Section 2][네트워크] SSR vs CSR (0) | 2023.05.30 |
| [Section 2][네트워크] 웹(WEB) 애플리케이션 (0) | 2023.05.30 |
| [Section 2][네트워크] 웹(WEB)의 구성 (0) | 2023.05.30 |


